Projects
Co-founder at DrivenData
DrivenData is a social enterprise that runs predictive modeling data science competitions for nonprofits, NGOs, and other mission-driven organizations. We also work directly with organizations of all kinds to help them make better decisions with their data.

Cookiecutter data science
A logical, reasonably standardized, but flexible project structure for doing and sharing data science work.
Ever tried to reproduce an analysis that you did a few months ago or even a few years ago? You may have
written the code, but it's now impossible to decipher whether you should use make_figures.py.old,
make_figures_working.py or new_make_figures01.py to get things done.
Here are some questions we've learned to ask with a sense of existential dread: Are we supposed to go in and join the column X to the data before we get started or did that come from one of the notebooks? Come to think of it, which notebook do we have to run first before running the plotting code: was it "process data" or "clean data"? Where did the shapefiles get downloaded from for the geographic plots? Et cetera, times infinity.
These types of questions are painful and are symptoms of a disorganized project. A good project structure encourages practices that make it easier to come back to old work, for example separation of concerns, abstracting analysis as a DAG, and engineering best practices like version control.
Rust crate for Markov Chain Monte Carlo diagnostics
The Rust mcmc library implements various MCMC
diagnostics and utilities,
such as Gelman Rubin potential scale reduction factor (R hat), effective sample size (ESS),
chain splitting, and others.
This crate is language agnostic and intended to work with the outputs of any MCMC sampler e.g. Stan, PyMC3, Turing.jl, etc).

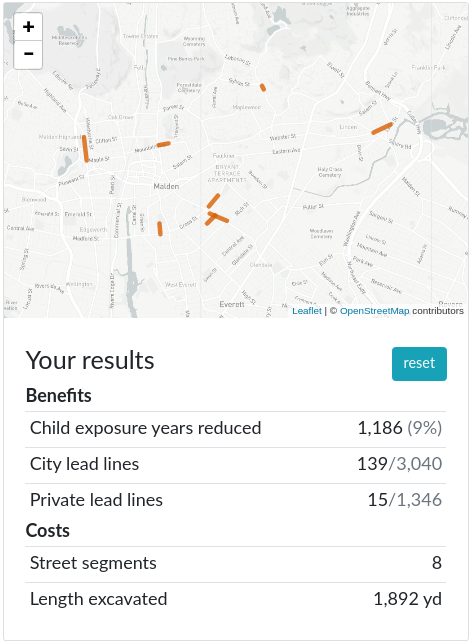
Analysis and planning tool for prioritizing lead mitigation projects in drinking water
The city of Malden, MA still has a large number of drinking water service lines which are made out of lead, either on the city side (under the street and sidewalk) or the private side (from under the sidewalk to the basement).
Lead exposure is hazardous to health, especially for children. Service lines made out of lead have the potential to expose inhabitants to lead toxicity. Because lead has disproportionately serious impacts on young children, the goal of this project is to explore the intersection of where the lead service lines are and where the city's children live.
In this project, I used city data to examine which parcels in Malden have both lead service lines and children living in the home, and then add up the years of possible exposure at the level of a street segment. This is all presented in a visualization tool which can help prioritize street segments to have the biggest public health impact.
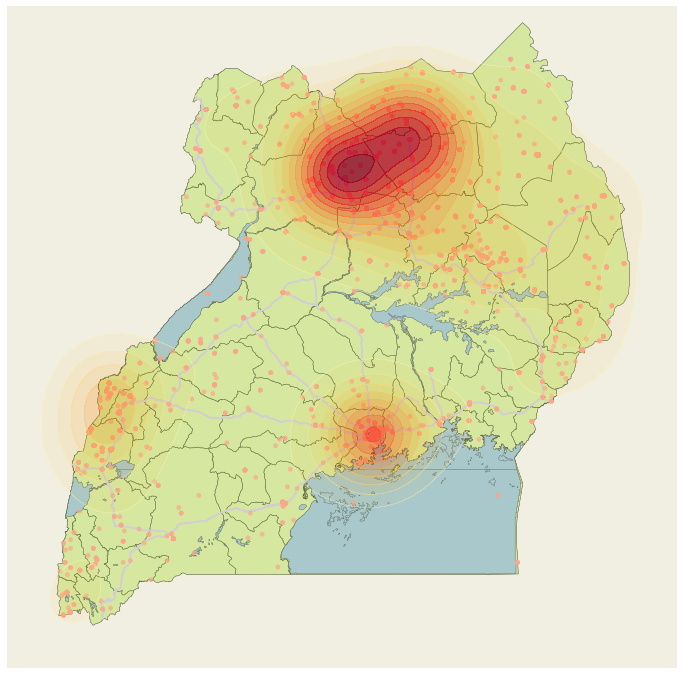
Modeling and simulating civil conflict in Uganda
We used data from ACLED (Armed Conflict Location and Event Data Project) and MCMC methods to simulate where civil conflicts happen in both space and time.
In the simulation part of this project, we treated the past data as an empirical distribution from which to sample. This worked out well, because the goal was less to predict exactly when and where conflicts take place than to create plausible scenarios for the optimization part of the project.
In the optimization part of this project, we used the temporal/geospatial conflict occurence model as a source of randomly sampled data points. We then used simulated annealing to get approximate solutions for a traveling salesman problem (visiting all conflicts for aid delivery) combined with a knapsack problem aspect (packing the aid vehicles with the right supplies).
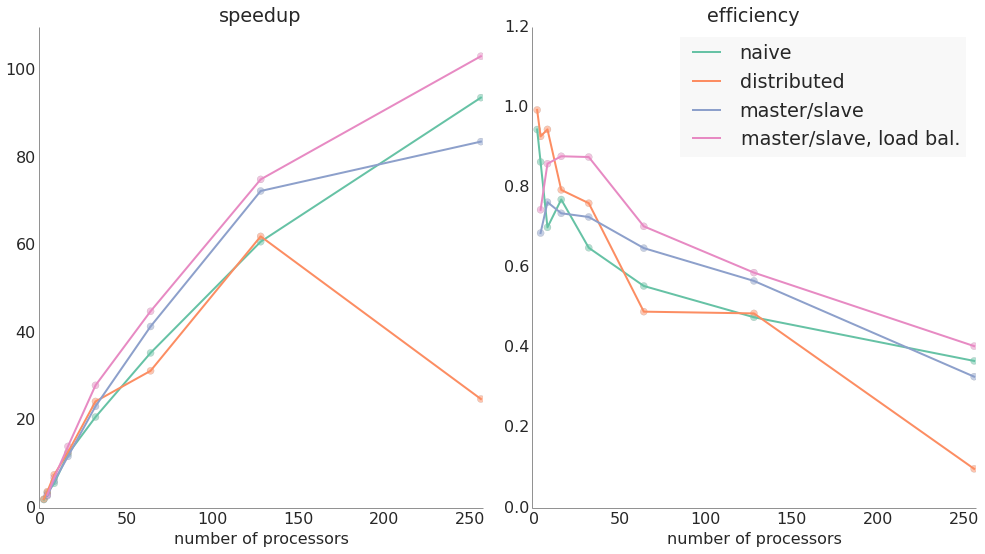
Parallelizing an Integer Linear Program (ILP) with MPI
We modeled an assignment ILP in a small private school where each grade of 80 to 100 students must be divided into four all-day class groups while satisfying several hard constraints (e.g. not placing certain pairs of students in the same class or making sure that all for classes have roughly the same number of students) and soft constraints (e.g. putting two specific friends together).
We achieved excellent speedups (over 100x) by parallelizing this problem. Subdividing the feasible region and using MPI to split up solving, we were able to move from a compute time of almost 4 hours down to about 2 minutes using a cluster of 256 processors. MPI proved a powerful and flexible way to parallelize LP solving.
Predicting workforce attrition in the U.S. Coast Guard
The United States Coast Guard (USCG) must decide each year how many enlisted personnel to promote in each specific rank and occupational specialty, as well as how many new recruits to bring on. These decisions are subject to many constraints, but the most important factor is the rate at which personnel leave the service.
The available data spanned FY 2005-2013. For each year, we had a snapshot of the entire enlisted workforce on the last day of the fiscal year with each member’s service information (e.g. time in service, occupational specialty, rank) and demographic information (e.g. gender, marital status, education level, etc).
The overall goal of the research was to forecast this unknown quantity in a robust and repeatable manner. We used Gaussian Mixture Models (GMMs), clustering, multi-level logistic regression, and other methods in order to forecast attrition.
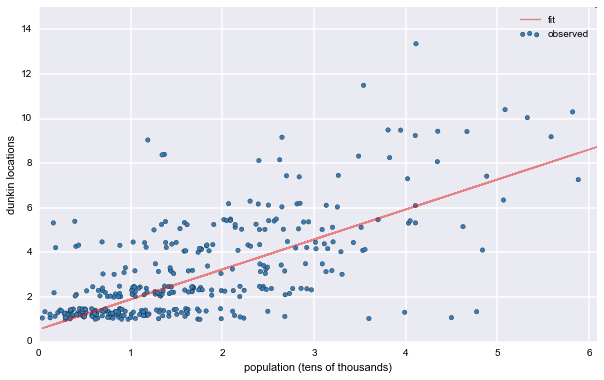
Analyzing Dunkin' Donuts' business with scraped data
I used data scraped from the Dunkin' Donuts online store locator along with openly available corporate disclosure documents and government data to delve into some of the fundamentals of Dunkin's franchising. For instance, a simple linear model with a mashup of store locations and US census data helps suggest which areas might support new, profitable franchises.
The post also demonstrates the use of some helpful Python packages like Basemap for GIS-like plotting, as well as command line tools such as pdftotext for getting useful information out of non-text documents.
django-hide-herokuapp
Django app for Heroku users designed to hide their *.herokuapp.com site from search engine results. Uses routing rules or custom middleware to make sure that the actual domain name gets into the SERPs and not the backup URL.
dotfiles-copier
A single script to copy all of your scattered dotfiles and config folders to a specified directory. Can automatically git commit changes.
Built on the lightweight click command line framework, and using an extremely simple YAML configuration inspired by Ansible's copy directive.
circlemud-world-parser
Long before massively multiplayer online games with realistic 3D graphics, MUDs were multi-user text-based games that were some of the first virtual worlds to be built on the internet. But these ephemeral worlds have been increasingly dying off, and with them goes much of the creativity that went into creating them. Each MUD often had thousands of lovingly crafted descriptions of spaces, people, and objects woven together into elaborate and immersive story lines.
CircleMUD was one of the most popular pieces of software designed for hosting a MUD. Written in 30,000+ lines of C, it was an impressive project for its time and was one of the early collaborative open source projects. It stored its objects (rooms, objects, characters, etc) in flat files based on a highly specific, custom format dating back to its predecessor DikuMUD.
This little digital archeology tool takes these old CircleMUD flat files and renders them in JSON, an approachable and widely used general purpose serialization format.
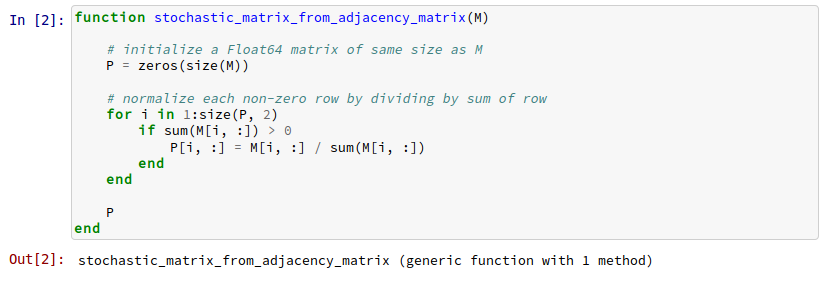
Syntax highlighting for IJulia notebooks in Pelican
The Pelican plugin for blogging with IPython notebooks didn't know how to highlight notebooks in languages other than Python. To make that work, I wrote some tests and the code to make them pass, then shot a quick pull request to the pelican-plugins repo.